Data Points
What are data points and how do I define them?
Data points are reoccurring bits of information within your website's content. If you're running a blog, the data points could be the author's name and the publishing date. If you're running an ecommerce site, it's worth defining such data points as price, brand, SKU, number of items left in stock, etc.
When you add data points for your website via the SS360 control panel, our crawler will pick up these data points while indexing your website and transform them into structured data to be displayed in your result snippets or to be turned into a filter or a sorting option across your search results.
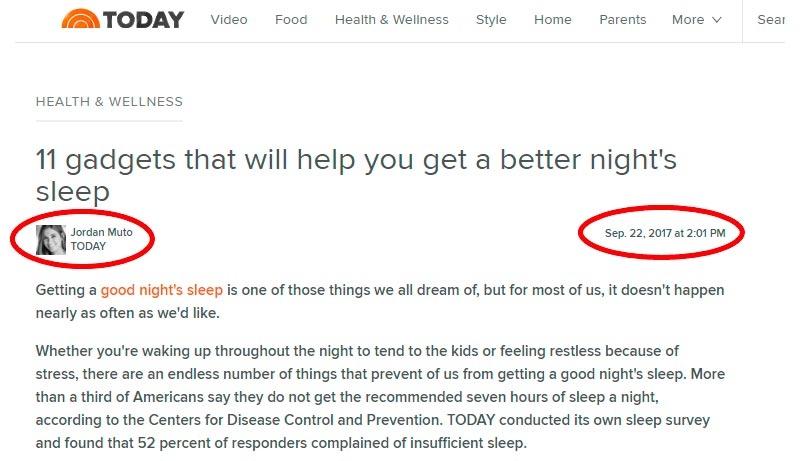
When looking at today.com, for example, you can see that their Health&Wellness posts always show the author of the article and the publishing date below the headline. With the data point feature, it's easy to extract this information from each article to generate a richer result snippet, making it possible for the user to easily see who wrote a specific result article or to sort the results by publishing date.
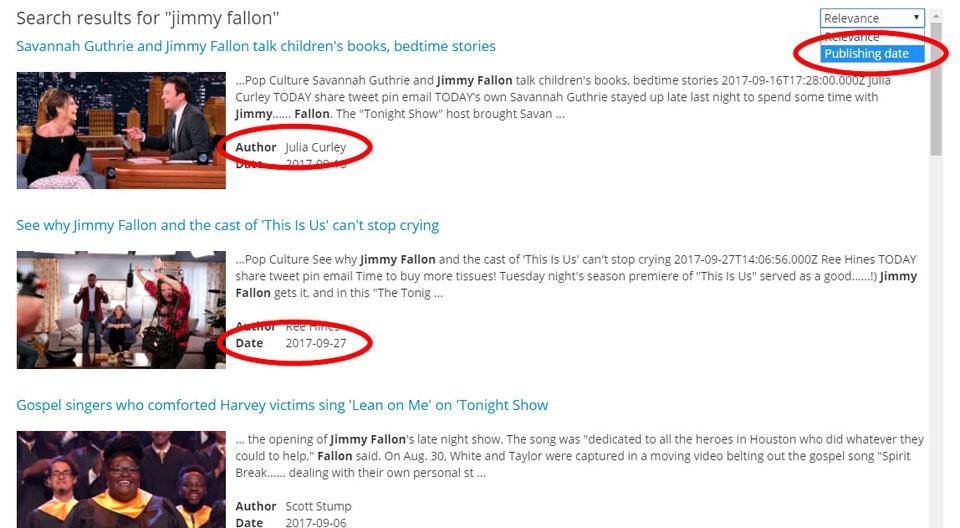
Visit Data Structuring -> Data Points in the SS360 control panel, where you can set up new data points.
Just hit the "Add New Data Point" button to add your first data point by filling out the template.
Your settings may look something like this:
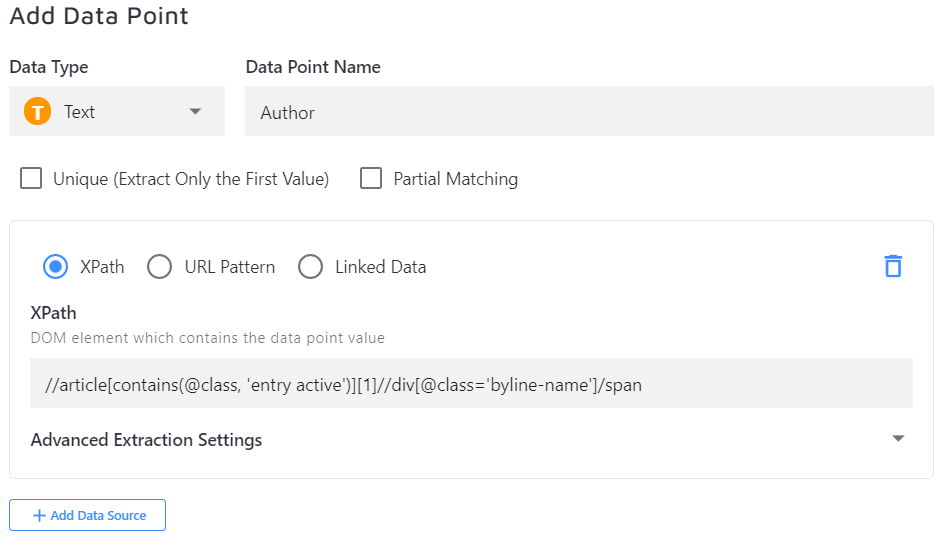
You can define text data points or numeric data points, as well as the date and boolean ones. Text data points are for displaying information within each search result, numeric data points can be used in the same way or they can be made into a sorting option (e.g. the publishing date, price, quantities, weight values, etc.). It's also possible to set the settings above are as follows:
Name: define a name for the data point. This name will be shown left of the data point.
Partial matching: when checking this option, the data point becomes substring searchable. That means, we'll return results if part of the data point matches the search query. It makes sense to use it on important information that is frequently searched, e.g. SKUs or article numbers.
For example, if "Partial Matching" is enabled, a product with an SKU data point "EU12345678" will also return as a result if someone searches for "12345678" (without quotes). It works the same with text data point, if the query is "burger", "cheeseburger" will also match if "Partial Matching" is enabled.
XPath: you'd have to enter a valid XPath expression to point the crawler to the element which contains the data point. Let's say you want to add an author filter. In this case, you would set "Name" to "Author" and then set the XPath to the DOM element containing the author's name. Every DOM element on your site described by this XPath will be analyzed and the information it contains will be extracted as a data point for this page.
You may also point the crawler to numeric information, such as date, weight, or price. This way, you can define a data point as a sorting option, an example of which will be shown later.
It's also possible to define data points via URL patterns, PDF meta data, linked data or content regex.
Unique: the XPath you provide could match multiple nodes on the page. Select this box to only pick the content from the first node determined by the XPath (this box should be checked by default).

Don't forget to hit the save button below the data point to save your configuration.
Important: you have to re-index your entire site to see the new data points.
How do I define data points?
There're a few sources you could point the crawler to, namely, XPath, URL Pattern, Linked Data, PDF Meta Data or Content Regex.
XPath: if you have the element which contains the data point in your site's content (either visible or invisible), you can enter a valid XPath expression to point the crawler to it. Every DOM element on your site described by this XPath will be analyzed and the information it contains will be extracted as a data point for this page. The easiest way to extract them would be to use the Google Chrome extension called "XPath Helper". If you’re interested, you can learn more about XPaths in our docs.
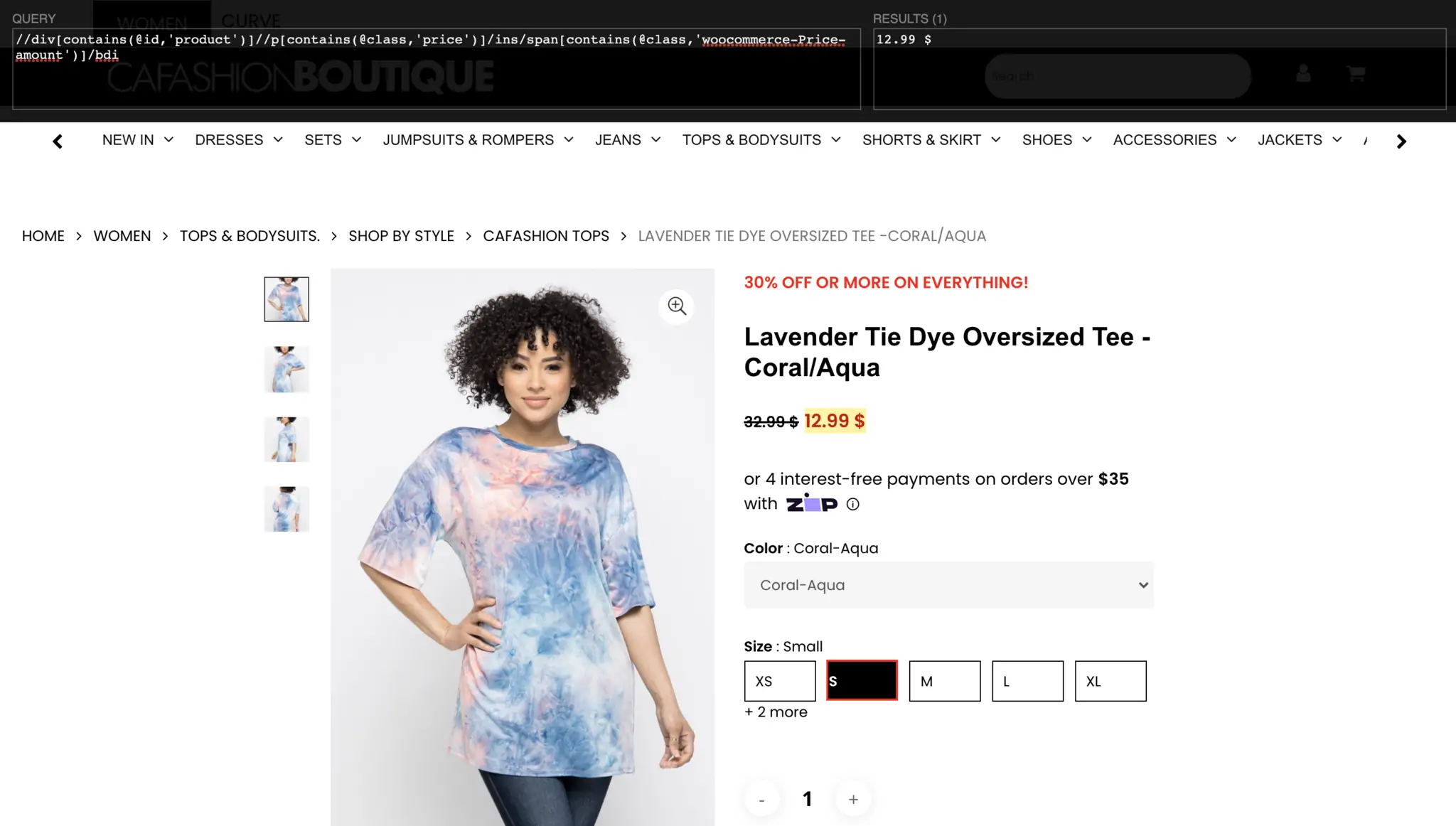
URL Pattern: if you want to extract a folder path in a page's URL as data point, you can use RegEx to extract it. For example, you can use https://mysite.com/([^/]+)/ to extract the first matching group.
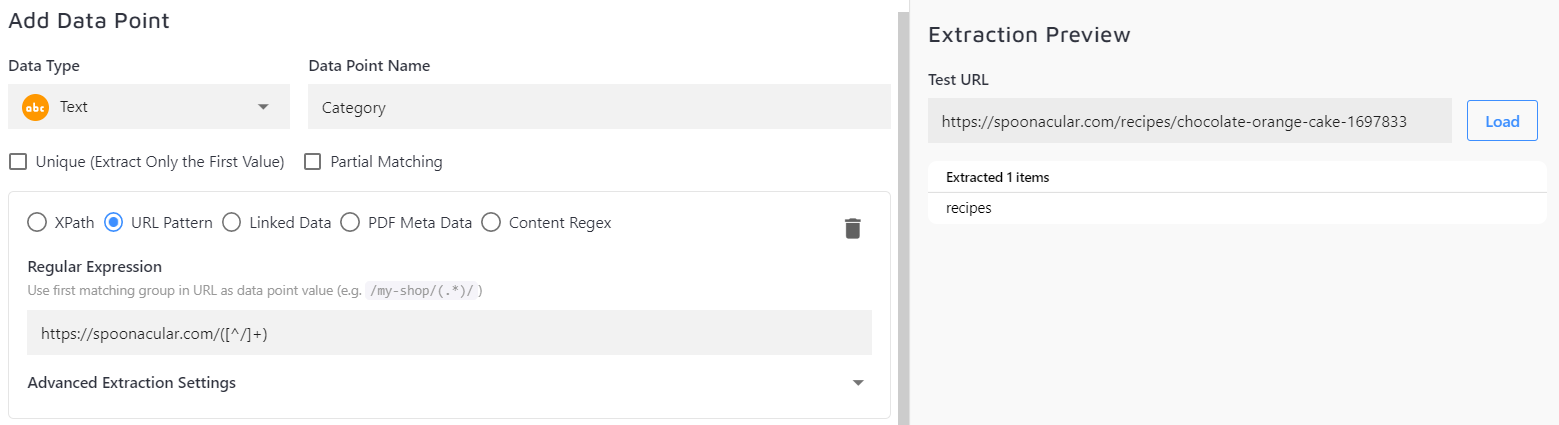
Linked Data: if you have JSON-LD on your site, you could also extract data point from it. The JSON-LD woud look like this:

You'd have to select the Condition type from the dropdown, if nothing matches the one on your site, type in yours. Let's say we wanna extract a data point for SKU, we'd need to extract the SKU property from the "Product" type:
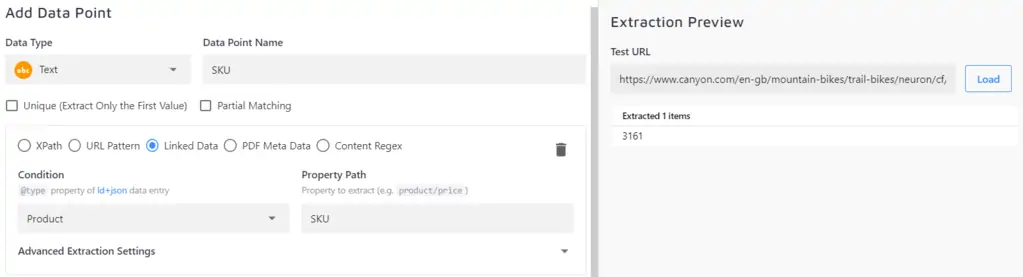
If you want to extract a data point that's not in the first level, e.g. the brand name "Canyon" in the above example, you'd have to define the nested property with a slash, i.e. brand/name:
PDF Meta Data:
Date data points
Date data points can be used for sorting. Let's extend the example from before and add a fate data point to display in the search results and to use as a sorting option.
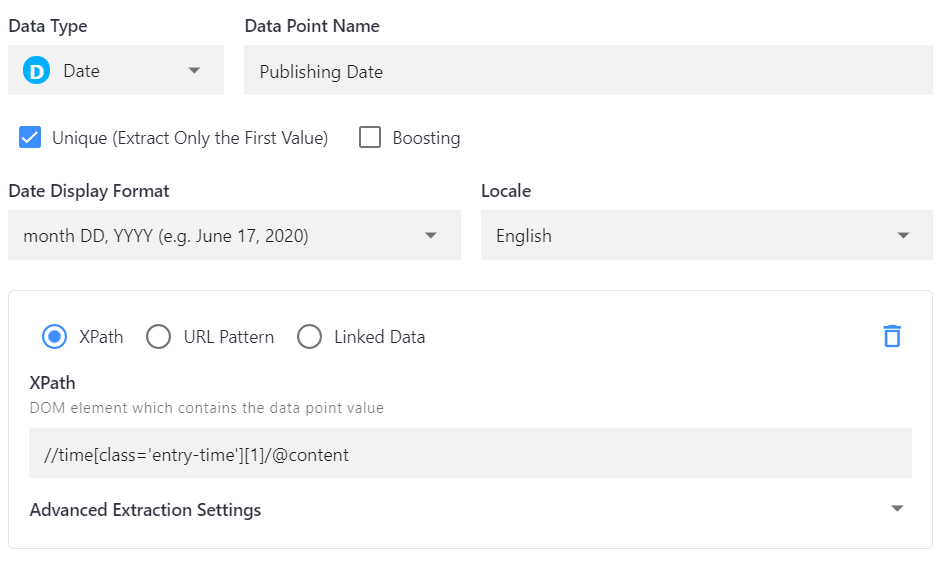
The XPath points to the publishing date of each article on today.com:
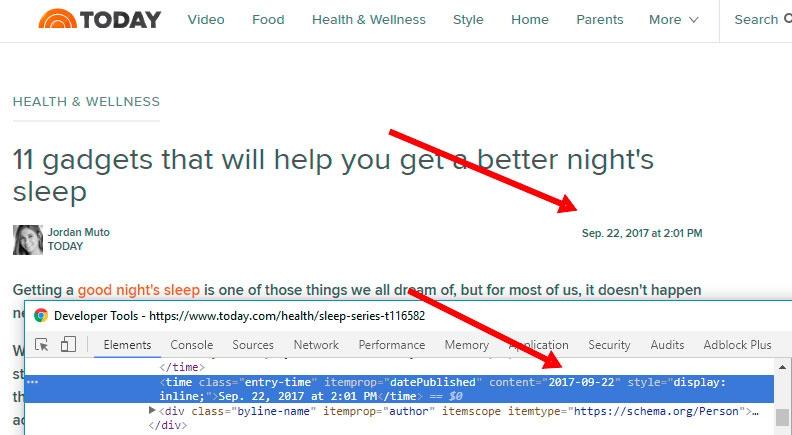
The publishing date is found on every article in the top right corner directly below the headline. The XPath chosen here extracts it directly from a meta attribute, which is part of the schema.org definition.
SS360 extracts this date twice and uses it in two different ways:
In the first setting, the XPath is used as a sorting option called "Publishing date". In this case, "Unique" is selected because, as explained earlier, we only want to extract the first result this XPath expression is giving back.
The second setting is configured to display the date directly under the "Author" data point in the search result. To achieve this, the "Unique" option is still selected since this is only regarding extraction. We still want to get the data from the first node if multiple nodes are found with the XPath expression.
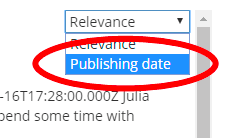
The "Unique" option is selected because, as explained earlier, we only want to extract the first result this XPath expression is giving back.

The "Unique" option is still selected since this is only regarding extraction. We still want to get the data from the first node if multiple nodes are found with the XPath expression.
By adding two data points that get their information from the same XPath leading to the same node, you can create both a sorting option and a richer search snippet with additional information.
Right below the data points we just defined, you will see the "Default Sorting" option. You now may choose to select your new numeric data point "Publishing date" as a default sorting option to show the newest article first in the search results.
Numeric data points
Similar to date data points, numeric data points can be used for sorting. You can extract price, rating, size dimensions, coordinates, or any other piece of numeric information. Numeric data points can also be used to extract dates, but that's somewhat redundant since a separate data point type specifically for dates is available.
A simple example: let's define a data point to extract product price:

In this example, the XPath points to the price of a product. Since the data point is strictly numeric, characters such as the $ dollar sign are automatically ignored.


When does it make sense to deselect the "Unique" option?
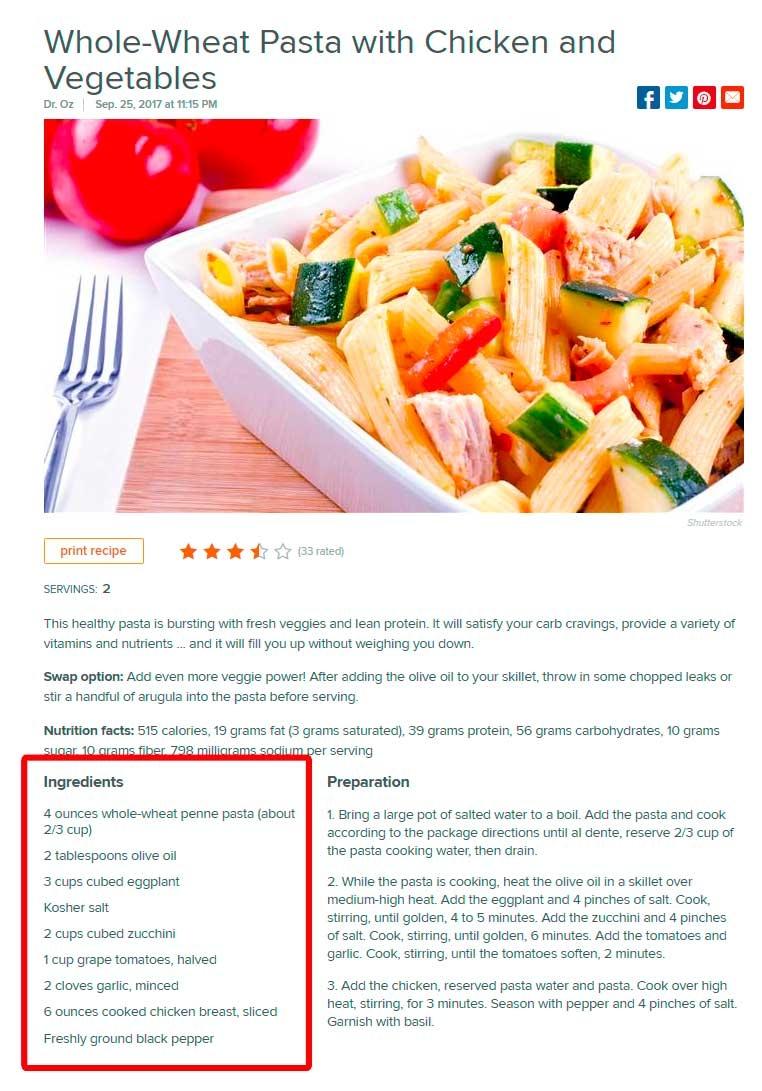
If you have multiple values you want to show within each search result, you may define one XPath to extract all nodes relevant for this information and leave the "Unique" option deselected. Let's look at an example on today.com when visiting the "Food" category. There you find many recipes for different dishes each with an ingredient list.
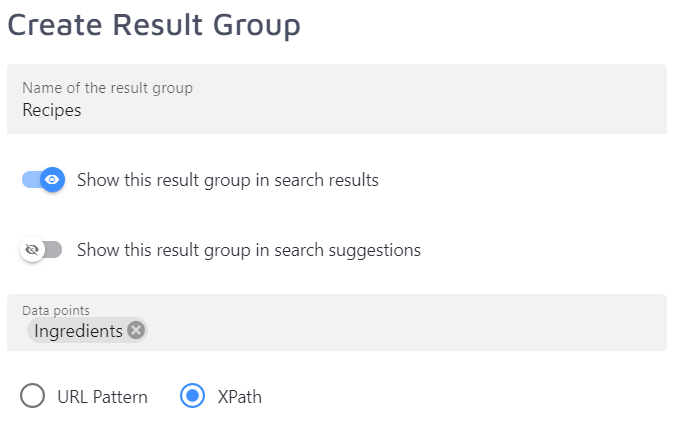
Result Group data points
To learn how to use data points for result grouping, you can refer to our result group tutorial.
Previously created data points can be used for result grouping, but it's also possible to enter an XPath or URL pattern while creating a new result group.
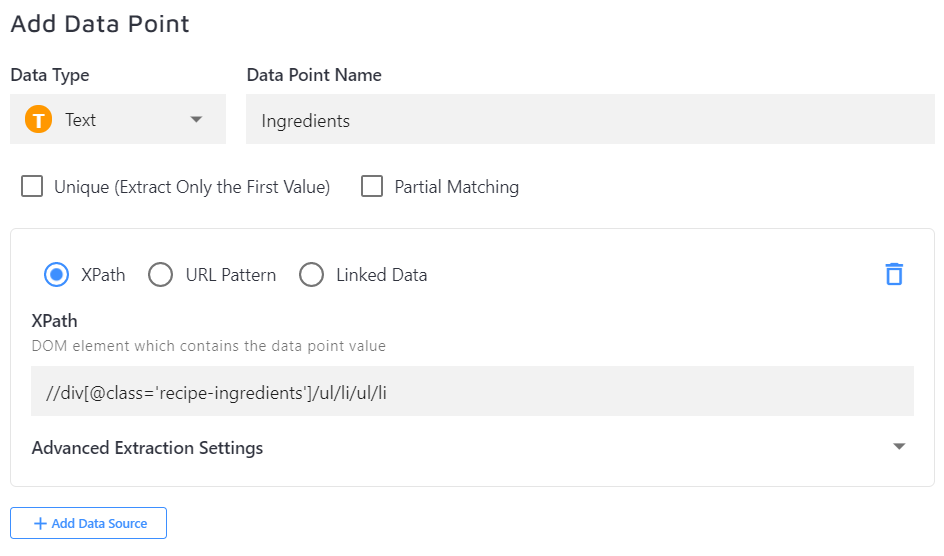
Each data point consists of a name--"Ingredients" in this case--and an XPath pointing to the desired content--in this case, the ingredient list.
Please note the "Unique" option is deselected in order to catch every ingredient.
When searching now for a recipe like "Z'paghetti Bolognese" we will find the ingredients listed directly in the search result:
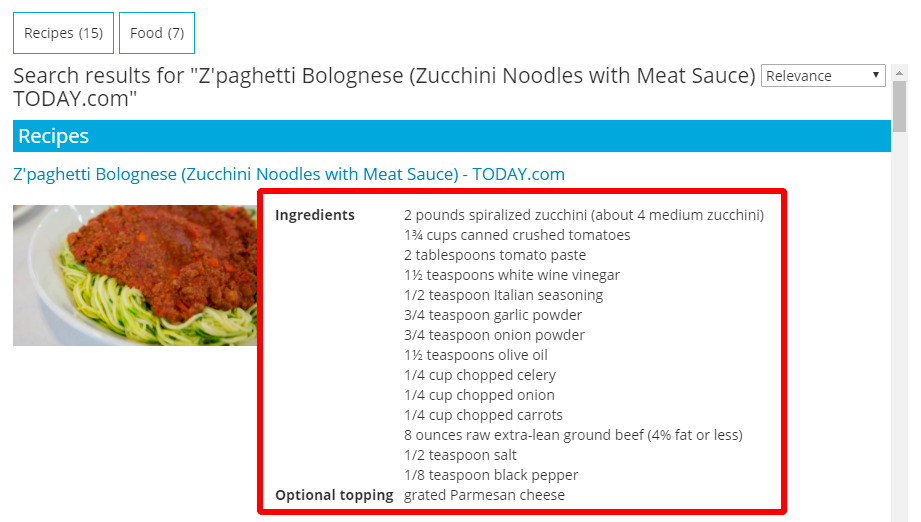
This can be tuned as much as you want, using whatever data points you have on your site. You may even place hidden tables or other elements to hold data not visible to the user, but extractable by the crawler, which will then be included in the search results.
Don't forget to re-index your entire site to let the changes take effect.
Show Data Points in Search Suggestions
var ss360Config = {
...
suggestions: {
dataPoints: {
Author: {html: '<b>Author:</b> #Author#', position: 1}
}
}
}suggestions: {
dataPoints: {
Author: {html: '#Author#', position: 1}
}
}The name between the # symbols has to exactly match the data point name so it is replaced with its value. Let's take another example: you want to show the "Category" and "Price" with the $ sign before the amount. You would adjust your configuration as follows:
var ss360Config = {
...
suggestions: {
dataPoints: {
'Category': {html: '<b>#Category#</b>', position: 1},
'Price': {html: '<span>$#Price#</span>', position: 2}
}
}
}By default, the data points would be shown below the result title, position: 2 below position: 1, etc. To see it in action, start typing e.g. granola or any other food item into the search box on this search example page. In this case, the "Calories" data point is displayed.
You can fine-tune the positioning of your data points by wrapping them in custom HTML and applying some CSS. For example:
suggestions: {
dataPoints: {
Price: {html: '<span class="price">#Price# USD</span>', position: 1}
}
}#unibox-suggest-box .unibox__selectable .unibox__extra {
position: relative;
left: 74px;
top: 20px;
}If you're using an older version of Site Search 360 (v10 and earlier), you have to apply the extraHtml parameter (now deprecated) instead of dataPoints. Here's how:
suggestions: {
extraHtml: '<b>Price</b>: #Price#'
}
Data points and API usage
When you use the SS360 HTTP REST API you can send data points within each uploaded page.
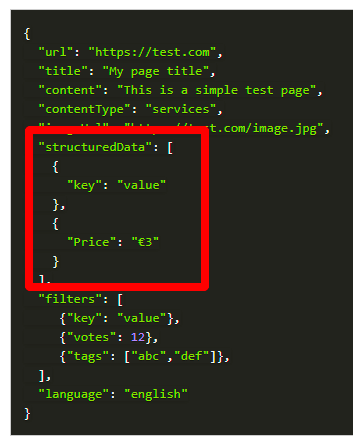
Use the structuredData array to send the objects of the data point within each page. You have to place a JSON object for each data point into the array. The data point JSON object must define the name, such as "Author" or "Publishing Date", and the corresponding value for this page.
Is anything still unclear? Please get in touch with us to help you via email (mail [at] sitesearch360.com), Gitter, or our chat widget on the main site.