Quick How-Tos - Data Sources
Indexing rules are directly responsible for the quality of your search results and can be set under the Data Sources section. Whenever you edit these settings, you need to re-index all configured sources for the changes to be applied. We also update your index automatically, the re-crawl/reindexing frequency depends on your plan.
What is indexing and how does the Site Search 360 crawler work?
A crawler, or spider, is a type of bot that browses your website and builds a search index that enables your search. A search index is a list of pages and documents that are shown as search results in response to a query that your site visitor types into a search box on your site.
The exact crawler behavior can be configured with "Website Crawling" or "Sitemap Indexing", or both at the same time.
Sitemap Indexing is a preferred indexing method. This means that, if we can detect a valid sitemap XML file for the domain you've provided at the registration, the Site Search 360 crawler will go to that sitemap - typically found at https://www.yoursite.com/sitemap.xml or https://www.yoursite.com/sitemap-index.xml - to pick up your website URLs listed there.
Note: The sitemap XML file should be formatted correctly for the crawler to process it. Check these guidelines.
If we cannot detect a valid sitemap for your domain, we automatically switch on the Website Crawling method: the Site Search 360 crawler visits your root URL(s) - typically the homepage - and follows outgoing links that point to other pages within your site or within the domains you've specified as the starting points for the crawler.
Indexing means adding the pages that were discovered by the crawler to a search index that is unique for every Site Search 360 project. Every project is referenced by its unique ID displayed under Account and is essential if you integrate the search manually.
Your Index log allows you to look up any URL and check if it's indexed.
Tip: If you notice that some search results are missing, the first thing to check is whether the missing URL is indexed. You can also try re-indexing it and see if it triggers any errors. With Sitemap Indexing, make sure the missing URL is included in your sitemap.
General principles:
The crawler does NOT go to external websites including Facebook, Twitter, LinkedIn, etc., but we do crawl your subdomains by default. For example, we would pick up the URLs from https://blog.domain.com if your start URL is https://domain.com. Turn the "Crawl Subdomains" setting OFF under Website Crawling if you'd like to exclude pages from your subdomains. You can also blacklist unwanted URL patterns.
The crawler always checks if there're any rules preventing link discovery. These rules can be set for all search engines (e.g. with the robots meta tag) or only applied for your internal search results, in which case you need to specify them under your Site Search 360 Settings. Check out how.
If you are blocking access for certain IPs but want the Site Search 360 crawler to have access to your site, please whitelist the following IP addresses in your firewall:
88.99.218.202
88.99.149.30
88.99.162.232
149.56.240.229
51.79.176.191
51.222.153.207
139.99.121.235
94.130.54.189
You can also look at the User Agent in the HTTP header. Our crawler identifies itself with this user agent string:
Mozilla/5.0 (compatible; SiteSearch360/1.0; +https://sitesearch360.com/)How do I index and search over multiple sites?
Let's assume you have the following setup:
A blog under http://blog.mysite.com/
Your main page under http://mysite.com/
And some content on a separate domain http://myothersite.com/
You now want to index content from all three sites into one index and provide a search that finds content on all of those pages.
This can be easily achieved by using one, or a combination of the following three methods:
Create a sitemap that contains URLs from all the sites you want to index or submit multiple sitemaps, one per line. In this case, our crawler only picks up the links that are present in your sitemap(s).
Let the crawler index multiple sites by providing multiple start URLs in Website Crawling. All the other settings, e.g. white- and blacklisting will be applied for all the specified domains.
You can also add pages from any of your sites via the API using your API key (available for Holmes plan or higher). You can either index by URL or send a JSON object with the indexable content.
Tip: consider setting up Result Groups to segment results from different sites or site sections. By default, content groups will be shown as tabs.
How do I set up sitemap indexing or root URL crawling?
Go to Website Crawling or to Sitemap Indexing and provide your start URL(s) or sitemap URL(s) in the respective fields.
With sitemaps, you can press "Test Sitemap" to make sure your sitemaps are valid and ready for indexing. This check also shows you how many URLs are found in your sitemap(s).
With Website Crawling, the only way to check the number of indexed pages and documents is to wait until a full site crawl is complete.
Switch on the "Auto Re-Index" toggle under the preferred crawling method. Hint: you can use both website crawling and sitemap indexing simultaneously.
Save your changes and re-index your site. When updating start page URLs or sitemaps, we recommend emptying the index first (press "Empty Entire Index") to rebuild the search index from scratch.
Note: The sitemap XML file should be formatted correctly for the crawler to process it. Check these guidelines.
How do I optimize the indexing process to make my search results update faster?
Depending on the number of pages you have on your site, the indexing time might constitute anything from mere minutes to hours. Since a full re-index is required every time you make changes to the project, the process might prove quite cumbersome if your project’s on the bigger side of things.
If that is the situation you find yourself in, the best way to move forward would be making Sitemap Indexing your primary method of updating the project.
Our crawler has an easier time dealing with sitemaps than sites in and of themselves because it doesn’t have to actively search for available URLs, following each link one by one. Instead, it can simply look through a list and add them to the Index Log in a fixed order. Nothing gets skipped and thus nothing goes missing from your search results.
Because all available URLs are present on a singular page, our crawler can instantly point out if any changes have been made to the project (say, an existing page is updated or an entirely new one is added) by analyzing the <lastmod> tag of each of those pages - this tag contains the date (and more often than not time) of the last modifications made to the project:
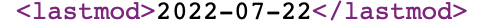
That is where the “Optimize Indexing” feature comes into play. If it’s enabled, whenever your project needs a re-index (and that frequency ranges from daily to monthly depending on your plan), the crawler would only go to those updated/added pages, significantly reducing the re-indexing time and the stress the servers on both sides are put under during the process.
In order to achieve this, you’ll need to take the following steps:
Upload your sitemap XML file formatted according to these guidelines under “Sitemap Indexing” and make sure that every page has a <lastmod> tag (optimization would be impossible if our crawler can’t see the information provided under this tag - it would be forced to check each page for changes or lack thereof instead)
Move the “Auto Re-Index” toggle to ON and tick the box for “Optimize Indexing”:
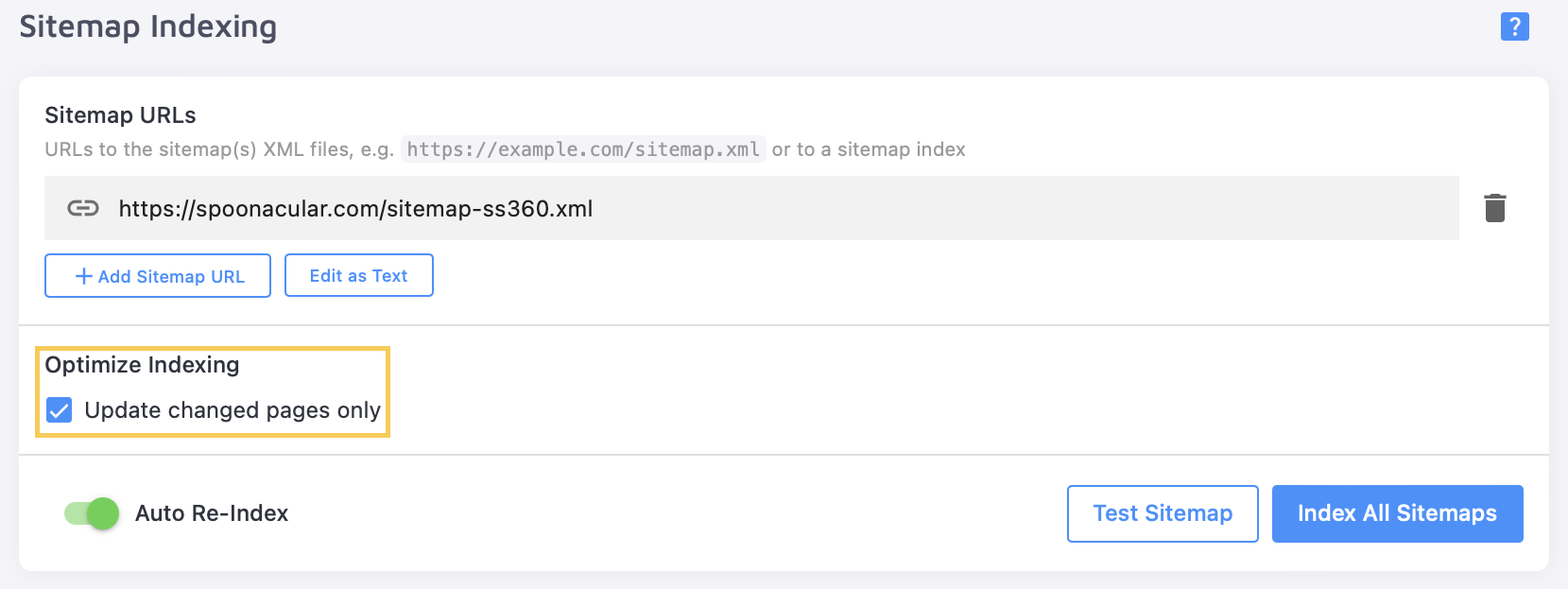
Disable auto re-indexing for your Root URL (if you have one) under “Website Crawling” - feel free to remove it completely if your sitemap has all the relevant pages
Keep in mind that the number of pages you have in the sitemap will still reflect on the indexing time. Even with optimized indexing a project with tens of thousands of URLs will require a bit of a wait. Otherwise, your regularly scheduled indexes should go smooth as a knife through butter.
There is one case in which our crawler ignores the “Optimize Indexing” setting and goes through all data sources with “Auto Re-Index” enabled in their entirety. A full re-index is run whenever you make any changes to the project which require a full update to be applied, like when you reconfigure your data sources, set up new content extraction rules, etc.
This happens because the <lastmod> tag becomes inconsequential - every single page needs to be checked and updated according to the new configuration settings.
Say, you create a new Result Group. It doesn’t matter whether the page is freshly added to the Index or has been there, totally unchanged, for months. Our crawler still has to go through all of them to see if anything fits the defining criteria you’ve set up for this Result Group.
If you’re actively updating a large project and staying patient has become a struggle, you can try using a URL List of your site’s most relevant content instead of other data sources.
This solution is far from ideal since you’d have to manually track your changes and update the list accordingly each time a page gets added to the site or deleted from it as well as each time your site’s pages are modified in any way. Our system also has a limit of 1000 pages for URL Lists because their primary purpose is indexing small batches of pages that aren’t found on the site or in the sitemap. For instance, if they’re located on a domain you’d rather not crawl or one that can’t be crawled in the first place, if those pages are landings or, say, PDFs which normally aren’t included in sitemaps, etc. So this option can be considered for a very short period of time only (and, of course, if other indexing methods fail).
How do I index secure or password-protected content?
If you have private content that you’d like to include in the search results, you need to authenticate our crawler so we’re able to access the secure pages. There are a few options to add search to password-protected websites:
Go to Website Crawling > Advanced Settings.
If you use HTTP Basic Authentication, simply fill out a username and a password.
If you have a custom login page, use the Custom Login Screen Settings instead (read below for the instructions).
You can also set a cookie to authenticate our crawler.
Whitelist our crawler's IP addresses for it to access all pages without login:
88.99.218.202
88.99.149.30
88.99.162.232
149.56.240.229
51.79.176.191
51.222.153.207
139.99.121.235
94.130.54.189
Provide a special sitemap.xml with deep links to the hidden content
Detect our crawler with the following User Agent string in the HTTP header:
Mozilla/5.0 (compatible; SiteSearch360/1.0; +https://sitesearch360.com/)Push your content to our HTTP REST API.
How do I crawl content behind a custom login page?
Go to Website Crawling > Advanced Settings > Custom Login Screen Settings. Activate the toggle.
Provide the URL of your login page, e.g. https://yoursite.com/login
Provide the login form XPath:
On your login page, right-click the login form element, press Inspect, and find its id in the markup. For example, you can see something like:
<form name="loginform" id="loginform" action=" https://yoursite.com/login.php " method="post”>So you'd take id="loginform" and address it with the following XPath:
//form[@id="loginform"]Define the authentication parameter names and map them with the credentials for the crawler to access the content.
Let's find out what parameter name is used for your login field first. Right-click the field and press Inspect. For example, you'll have:
<input type="text" name="log" id="user_login" class="input”>So you’d take
logand use it as Parameter Name. The login (username, email, etc.) would be the Parameter Value. Click Add and repeat the same process for the password field.Save and go to the Index section where you can test your setup on a single URL and re-index the entire site to add the password-protected pages to your search results.
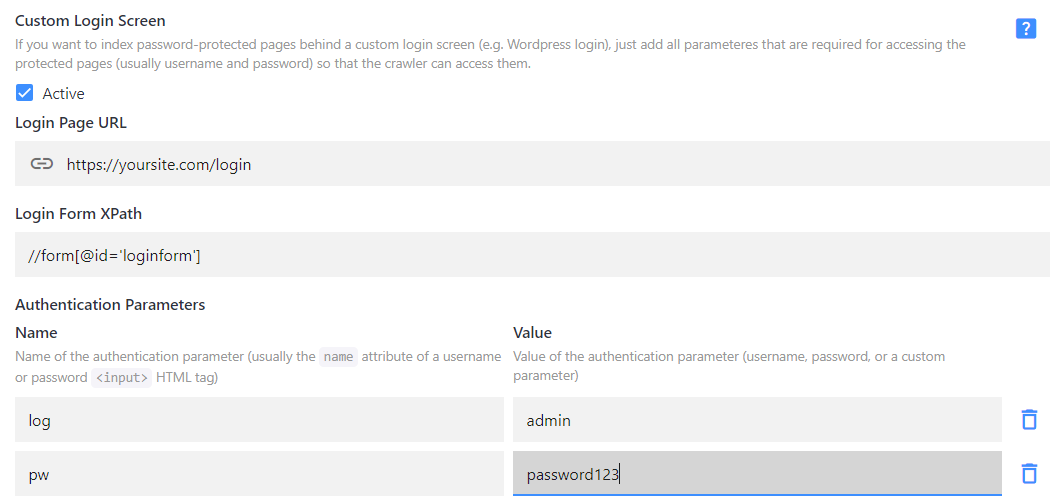
Some login screens have a single field, usually for the password (e.g. in Weebly), in which case you'd only need one parameter name-value pair.
How do I index JavaScript content?
The Site Search 360 crawler can index content that is dynamically loaded via JavaScript. To enable JS crawling, activate the respective toggle under Website Crawling > Advanced Settings, and re-index your site.
Note: JS crawling is an add-on feature and it isn't enabled for free trial accounts by default. Please reach out if you need to test it before signing up for a paid plan.
JavaScript crawling also takes more time and more resources to index JavaScript-rendered content. If there are no search results or some important information seems missing unless you activate the JavaScript Crawling feature, make sure to add it to your Custom Plan options to be able to use it after your trial period expires.
Alternatively, you can push your content via our API.
How do I avoid duplicate indexed content?
If you find duplicate content in your index, there are a few options under Website Crawling and Sitemap Indexing to help you resolve that.
For your changes to take effect you'll need to re-index your site. We recommend clearing the index (Index -> Empty Entire Index) first to make sure the duplicates are removed.
Use Canonical URL
Canonical tags are a great strategy to avoid duplicate results not only for your internal site search but also in Google and other global search engines. Learn more about the changes required on your side.
So let's assume you have 3 distinct URLs but the content is exactly the same:
You don't want to have 3 times the same search result so you would add the following tag to the first two pages to indicate that they refer to the same 'master' URL:
<link rel="canonical" href="
http://mysite.com/page1
" />Once this is set up correctly on your site, turn on the "Use Canonical URL" toggle and re-index your site.
Ignore Query Parameters
Let's assume you have these two URLs with the same content:
Even though these URLs refer to the same page, they are different for the crawler and would appear as separate entries in the index. You can avoid that by removing URL parameters that have no influence over the content of the page. To do so, turn ON "Ignore Query Parameters".
Note: The setting cannot be applied safely if you use query parameters:
For pagination (?p=1, ?p=2 or ?page=1, ?page=2 etc.)
Not only as a sorting method (?category=news), but also to identify pages (?id=1, ?id=2, etc.)
In these cases ignoring all query parameters might prevent our crawler from picking up relevant pages and documents. We can recommend the following strategies instead:
Submit a sitemap with 'clean' URLs and switch from Website Crawling to Sitemap Indexing, which is a faster indexing method and usually produces cleaner results.
Add pagination to No-Index Patterns (e.g.,
\?p=) and blacklist other query parameter patterns under Blacklist URL Patterns. Here's how to do it.
Lowercase All URLs
Before turning the setting ON, make sure your server is not case-sensitive. Example:
Remove Trailing Slashes
Only turn this setting ON if the URLs with and without the slash at the end display the same page:
What is the 'noindex robots meta tag' and how does it affect my search results?
When you don't want Google to pick up specific pages or your entire site (e.g. when it's still in development), you might already be using the noindex robots meta tag:
<meta name='robots' content='noindex,follow' />If you want to keep your site pages hidden from Google while allowing Site Search 360 to index them, simply turn on the Ignore Robots Meta Tag toggle under Website Crawling and Sitemap Indexing.
If it's the other way round, i.e. you want to keep the pages visible in Google but remove them from your on-site search results, use the blacklisting or no-indexing fields.
Alternatively, you can add a meta tag to the selected pages and use ss360 instead of robots:
<meta name="ss360" content="noindex" />Important! Make sure you're not blocking the same pages in your robots.txt file. When a page is blocked from crawling through robots.txt, your noindex tag won't be picked up by our crawler, which means that, if other pages link out to the no-indexed page, it will still appear in search results.
If you want Site Search 360 to show or ignore specific pages in your search results, use whitelisting, blacklisting, or no-indexing options as described below. You can find them under Website Crawling and Sitemap Indexing.
General rules:
URL and XPath patterns are interpreted as regular expressions so remember to put a backslash (\) before special characters such as
[]\^$.|?*+(){}.Important! When you modify Crawler Settings, remember to go to the Index section and press "Re-index Entire Site" for the changes to take effect.
How do I whitelist, blacklist, and no-index URLs to control which pages and documents are shown in search results?
If you want to remove specific pages or documents from your site search results (without deleting them from your website), you can blacklist or no-index unwanted URL and URL patterns, or whitelist a specific sub-domain or folder on your site.
You can update these features under both Website Crawling and Sitemap Indexing.
Please note that URL and XPath patterns are interpreted as regular expressions so remember to put a backslash (\) before special characters such as []\^$.|?*+(){}.
Blacklist URL patterns:
Tell the crawler to completely ignore specific areas of your site. For example, you want our crawler to ignore certain files or skip an entire section of your website. Go ahead and put one pattern per line here:
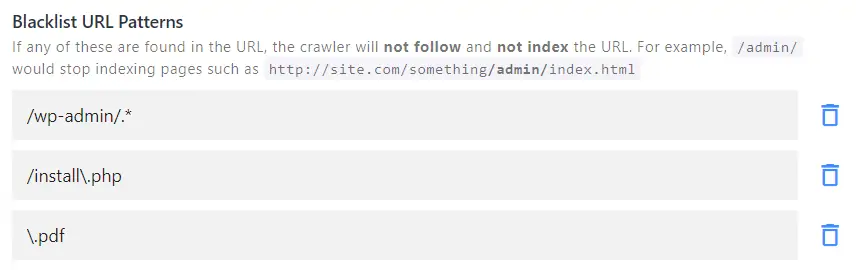
Note: blacklisting takes priority over whitelisting. If there's a conflict in your settings, the whitelisted patterns will be ignored.
Whitelist URL patterns:
Restrict the crawler to a specific area of your site.
For example, you want to limit your search to blog pages only. If you whitelist
/blog/, our crawler won't index anything except for the URLs containing/blog/. This can also be useful for multilingual sites.Depending on your URL structure, you could, for instance, use the following patterns to limit the search to French-language pages only:
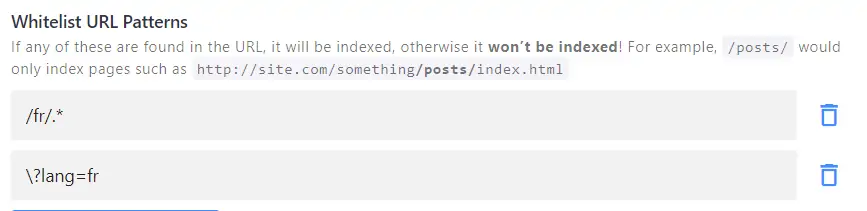
Note: make sure that your start page URL matches your whitelisting pattern (e.g. https://website.com/blog/ or https://website.com/fr/). If the start page URL itself doesn't contain the whitelist pattern, it will be blacklisted -> nothing can be indexed -> no search results.
No-index URL patterns:
This setting is the same as
noindex,followrobots meta tag: the crawler follows the page and all the outgoing links but doesn't include the no-indexed page in the results. It is different from blacklisting where the crawler fully ignores the page without checking it for other "useful" links.For example, URLs that are important for the search are linked from the pages you want to exclude (e.g. your homepage, product listings, FAQ pages. Add them as no-index patterns):

Note the
$sign: it indicates where the matching pattern should stop. In this case, URLs linking from the escaped page, such as/specific-url-to-ignore/product1, will still be followed, indexed, and shown in search results.Note: no-index URL pattern takes priority over whitelisting. If there's a conflict in your settings, the whitelisted patterns will be ignored.
No-index XPaths:
Sometimes you need to no-index pages that do not share any specific URL patterns. Instead of adding them one by one to no-index URL patterns (see above), check if you can no-index them based on a specific CSS class or ID.
For example, you have category or product listing pages that you wish to hide from the search results. If those pages have a distinct element which isn't used elsewhere, e.g. <div class="product-grid"></div>, add the following No-Index XPath: //div[@class="product-grid"]
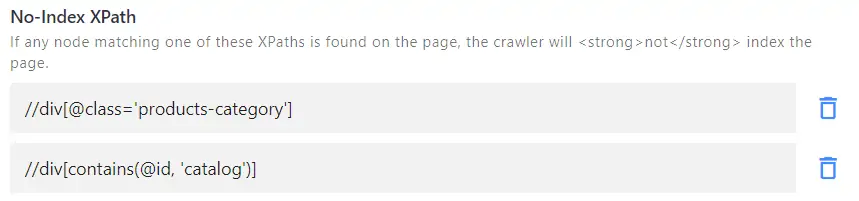
In this case, the crawler would go to the "product-grid" pages, then follow and index all the outgoing URLs, so your product pages will get indexed and shown in the results. Learn how to use XPaths or reach out to us if you need any help.
Note: using a lot of No-index URL patterns or No-Index XPaths slows down the indexing process, as the crawler needs to scan every page and check it against all the indexing rules. If you're sure that a page or a directory with all outgoing links can be safely excluded from indexing, use the Blacklist URL pattern feature instead.
Whitelist XPaths:
Similar to Whitelist URL patterns, it restricts the crawler to a specific area of your site.
If you want to limit your search to some pages, but they do not share any specific URL patterns, then whitelist XPaths come in handy.
For example, the following XPath limits the search to Russian-language pages only:

Note: whitelist XPath takes priority over no-index XPath. If there's a conflict in your settings, the no-index XPaths will be ignored.
How do I use the URL List?
URL List can be found under Data Sources.
For one reason or another, our crawler may fail to pick up some URLs. In this case, you can add pages to the index manually.
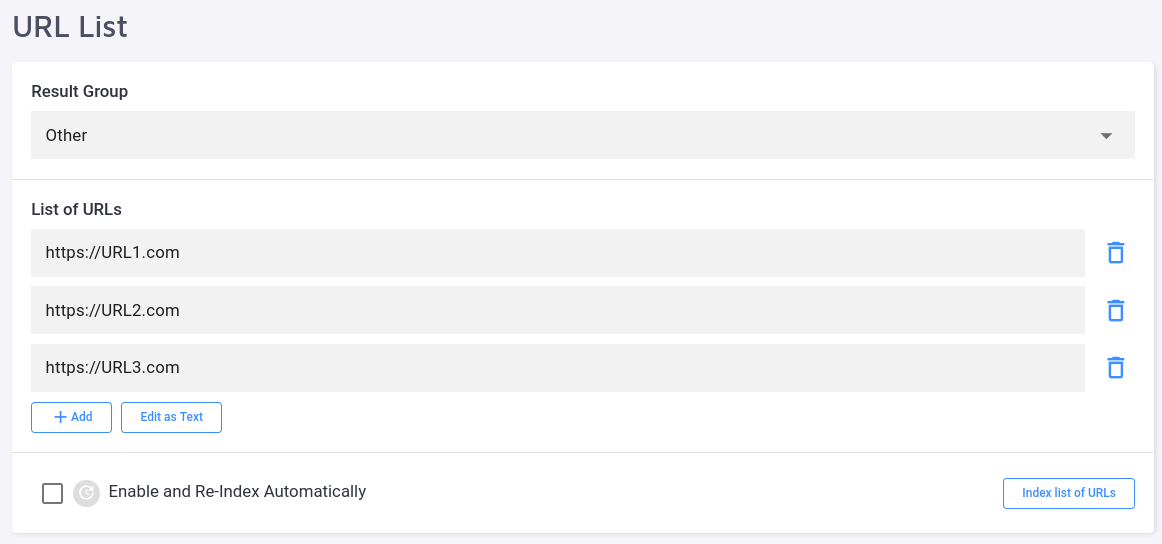
This method is different from adding URLs one by one under Index:
The URL List isn't purged upon a full re-index, whereas links added manually under the Index section are deleted from the index.
The URL list allows adding links in bulk by clicking on "Edit as Text", instead of pasting them individually.
How do I control what images are displayed in search results?
By default, we use a striped background to indicate a missing image. This happens when none of our default extraction rules have led to a meaningful image (e.g., we ignore icons and footer logos by default). We also do not support images that are set as background property in CSS.
There are a few ways to control which pictures are used as search result thumbnails.
1. If you want to show a specific thumbnail for every result page, you can define it by adding or updating the Open Graph (og:image) meta tags with the desired image on your webpages. Usually, SEO plugins, as well as modern CMS systems, offer this functionality: the same images would be shown when you share links from your website in social media and messengers. You can learn more about Open Graph tags.
Once you have the meta tags set up, you'll simply need to re-index your site for the crawler to pick them up.
2. You can get rid of empty image containers by setting the placeholderImage parameter to null, it goes under results in your ss360Config code:var ss360Config = {...results: {placeholderImage: null}
3. You can also specify a custom placeholder image URL by using this instead:
results: {placeholderImage: "https://placekitten.com/200/300"}
4. Finally, you can fine-tune the rules the crawler uses to pick up images from your site by adjusting Image XPaths under Data Structuring -> Content Extraction. You can learn more about XPaths here.
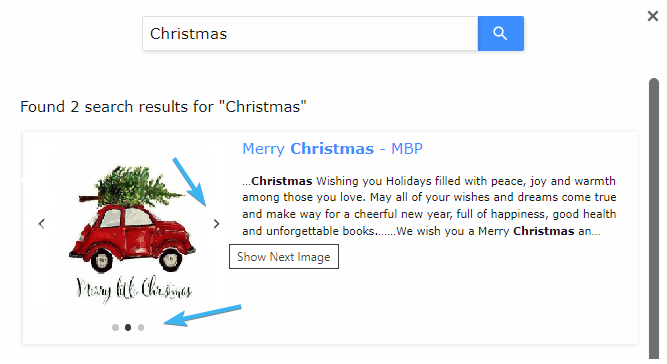
If you want to display two or more images for one search result, you can set this up with Alternative Image Extraction.
You'll need to point our crawler to the alternative images displayed on your site under Content Extraction > Alternative images XPath. Here is an example of how results can look like after configuring it:
Main image:
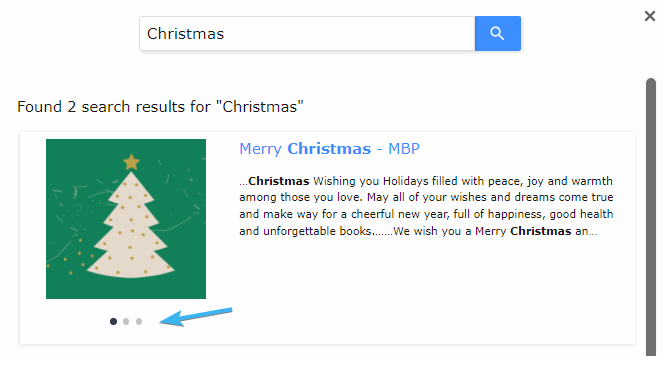
Alternative image:
How do I fix Client Error 499?
When indexing your site's pages, we need to send HTTP requests to your web server. Every request received by the server gets a 3-digit status code in response. You can check these response codes in your Index Status table.
Client errors are the result of HTTP requests sent by a user client (i.e. a web browser or other HTTP client). Client Error 499 means that the client closed the connection before the server could answer the request (often because of a timeout) so the requested page or document could not be loaded. Re-indexing specific URLs or your entire site would usually help in this case.
This error can also occur when our crawlers are denied access to your site content by Cloudflare. Please make sure to whitelist our crawler IPs at Cloudflare (under Firewall > Tools):

Here's the list of IPs used by our crawlers:
88.99.218.202
88.99.149.30
88.99.162.232
149.56.240.229
51.79.176.191
51.222.153.207
139.99.121.235
94.130.54.189
You can also allow us as a User Agent at Cloudflare:
Mozilla/5.0 (compatible; SiteSearch360/1.0; +https://sitesearch360.com/)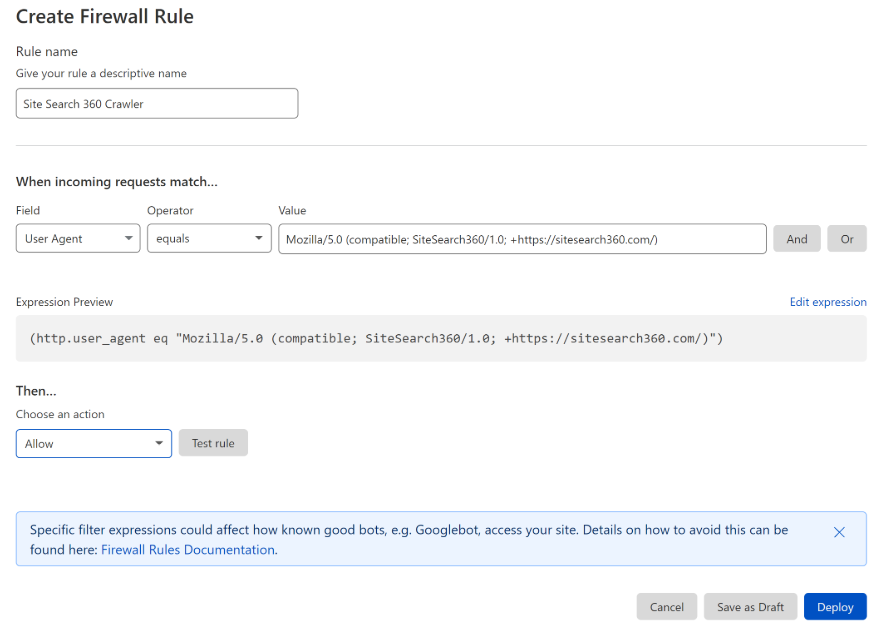
Note: Cloudflare can be set up as part of your CMS (Content Management System - e.g. WordPress, Magento, Drupal, etc.). If you're not sure, please check with your CMS and ask them to whitelist Site Search 360 crawler IPs for you.
How do I fix Client error 403?
The 403 error means that when our crawler requests a specific page or file from your server, the server refuses to fulfill the request.
If whitelisting our crawler IP addresses and allowing us as a User Agent haven't helped, the issue may be related to your HTTP method settings.
Some Content Management Systems, e.g., Magnolia CMS, block HEAD requests by default. Try adding HEAD to the allowed methods so your documents can successfully be reached by the crawler and added to your search index.